本文由Thijs Nieuwdorp和Tom Drabas撰写。
-
Thijs Nieuwdorp是Xomnia的数据科学家,也是《Python Polars: the Definitive Guide》的合著者。
-
Tom Drabas是NVIDIA的高级开发者关系经理。
改进Polars GPU引擎
Polars的核心理念之一是充分利用机器上所有可用的核心。构成大量计算能力的一种计算核心是图形处理单元,即GPU。Polars以其高性能而闻名,现已通过与NVIDIA的合作突破了其极限,通过集成GPU引擎释放了更多能力,该引擎有望加速计算密集型查询。其核心是利用NVIDIA cuDF,这是一个基于CUDA平台构建的DataFrame库,将分组、连接和字符串操作等密集型操作卸载到现代NVIDIA GPU的并行架构上。用户几乎无需更改代码,只需使用以下参数指定GPU引擎即可触发GPU执行:.collect(engine=”gpu”)。如果操作不兼容,它会优雅地回退到正常的CPU执行,从而保证结果。
通常,GPU引擎通过将数据加载到视频随机存取存储器(VRAM),即GPU的工作内存中来执行计算。这与GPU的计算核心之间有着闪电般的连接。不幸的是,与系统RAM相比,GPU通常可用的VRAM更少。这限制了GPU引擎在处理大型数据集时的能力。RAPIDS团队正在不断开发新功能来缓解这个问题。他们最近实现的技术之一是引入了CUDA的统一虚拟内存(UVM)。
但是,UVM是否允许进行大于VRAM的操作?它会带来任何性能开销吗?让我们一探究竟。
大于VRAM
统一虚拟内存将系统的RAM(也称为主机内存)与GPU的VRAM(也称为设备内存)结合起来。这使得GPU引擎能够使用比VRAM更大的内存池,从而防止内存不足错误。要了解此功能的工作原理,您首先需要深入了解内存的一般工作方式。为此,您需要了解几个关键术语
内存中存在的每个对象都有一个分配的内存地址。内存地址空间被划分为页面或页文件,它们是固定大小的连续内存块。地址空间可以大于RAM,在这种情况下,例如,页面可以驻留在辅助存储器中,以允许地址空间的聚合大小超过系统的物理内存。在UVM的情况下,这种辅助存储器就是RAM。将页面存储在辅助存储器上并从中检索的技术称为交换。
当应用程序试图访问当前未映射到VRAM的地址时,会发生页面错误。为了处理此错误,GPU拥有一个页面迁移引擎,它将负责将正确的页面交换到VRAM中。下面是对其内部工作原理的严重过度简化。
假设我们要根据橙子和苹果各自的id列进行连接,以比较这两个数据集。然而,我们刚刚对苹果的名称和重量进行了分析,这意味着目前只有苹果数据加载在VRAM中。
为了执行连接,应用程序请求“地址4”,其中包含橙子的id列数据。然而,该列目前驻留在RAM中,导致了页面错误。为了将其交换到VRAM中,迁移引擎将执行以下操作
- 通过将最近最少使用的页面从VRAM交换到RAM来释放VRAM。
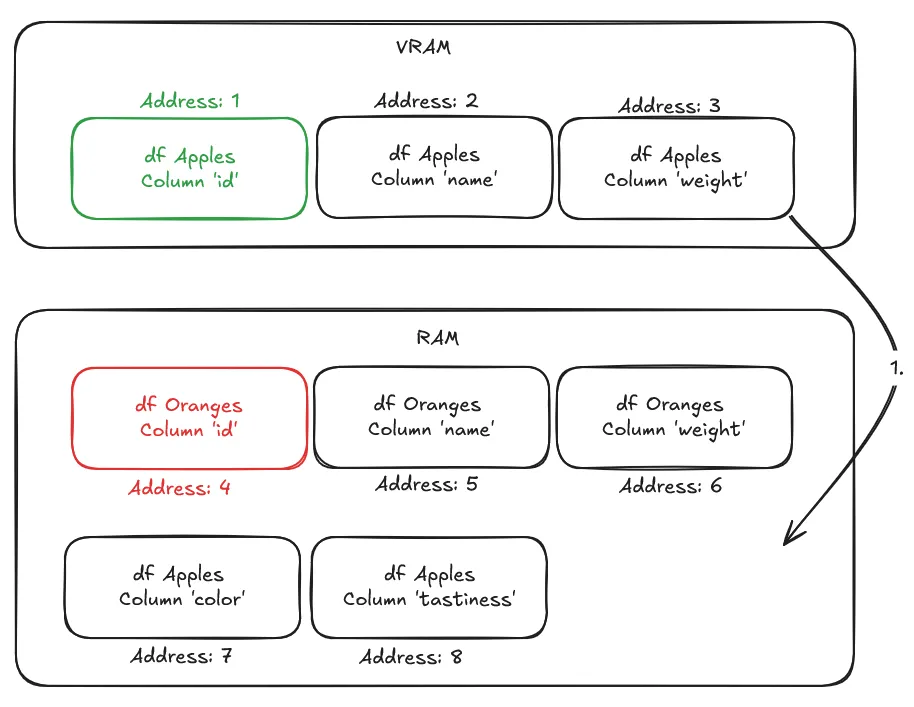
- 将新释放的VRAM映射到应用程序试图访问的“地址4”。
- 将本应位于该地址且包含“id”列的页面从RAM交换到VRAM中。
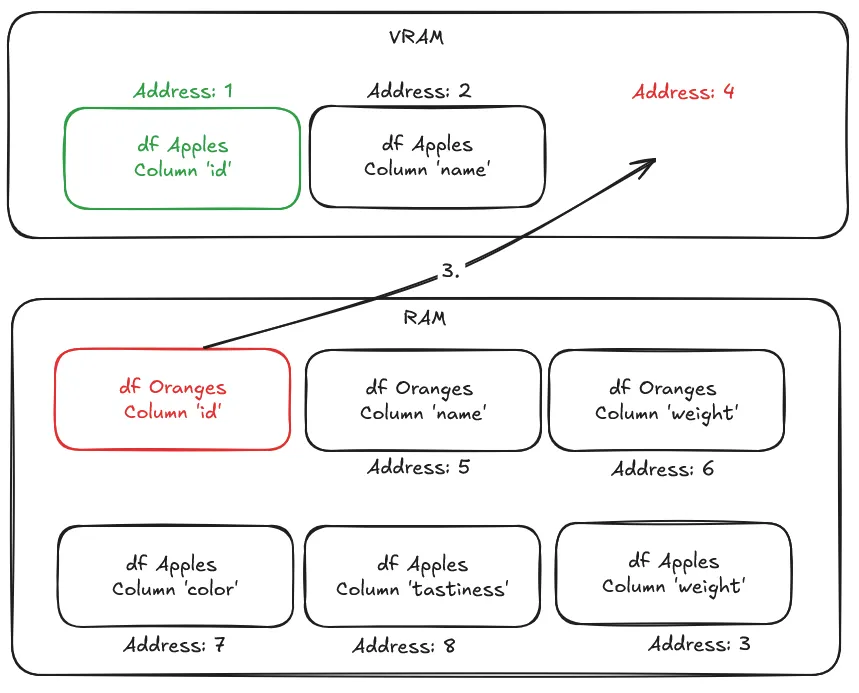
- 重试访问内存地址,并从中断处恢复程序。这次,它成功检索到了数据。
在进行此交换时,程序会暂停,因此每当发生页面错误时,都会产生性能损失。NVIDIA驱动程序采用启发式算法来维护数据局部性,这是一种将数据存储在靠近将要使用它的处理单元附近的做法,从而减少数据密集型应用程序中的数据移动和延迟。这可以防止过多的页面错误。除了这些启发式算法之外,您还可以使用CUDA API将特定对象预取到VRAM中,以防止页面错误发生。在这种情况下,Polars的CUDA加速引擎会根据正在执行的查询类型,指示CUDA API预取数据,以最大程度地减少页面错误。
所有这些技术都允许在“大于VRAM”的数据集上进行GPU计算,但由于页面迁移,可能会牺牲一些性能。为了帮助您为自己的用例选择最佳配置,让我们进一步了解不同配置的优缺点,并通过基准测试来检验它们。这些配置基于RAPIDS内存管理器(RMM)。
构建块:RMM的内存资源
将RMM的内存资源视为内存管理工具箱中的基本工具。您可以混合搭配它们,为您的特定需求创建理想的设置。虽然有很多,但本文将重点关注以下资源
CudaMemoryResource:默认分配器 这是最直接的内存资源。它直接传递给标准的CUDA内存函数:cudaMalloc()用于在GPU上分配内存,cudaFree()用于释放内存。它可靠且是一个很好的基线,但对于有许多小额分配的应用程序来说,通常不是最快的。
ManagedMemoryResource:通往统一虚拟内存(UVM)的门户 此资源利用cudaMallocManaged()来使用NVIDIA的统一虚拟内存系统。UVM允许您的CPU和GPU共享单个内存空间。这简化了您的代码,让CUDA系统能够按需在主机(CPU)和设备(GPU)之间自动迁移数据。
PoolMemoryResource:性能优化器 这是一个“子分配器”,可显著加速内存操作。PoolMemoryResource不会每次需要内存时都向GPU驱动程序请求,而是预先分配一大块GPU内存(即“池”)。随后的分配请求将迅速从该池中得到满足。这消除了频繁调用CUDA驱动程序所带来的显著开销,使其成为高性能工作流程的关键。
PrefetchResourceAdaptor:主动提示器 这是一个“适配器”,它封装了另一个内存资源,通常是使用托管内存的资源。它的作用是通过预取数据,向CUDA系统提供性能提示。通过在数据被访问之前告知系统数据将会在哪里被需要(并主动将其移动到GPU),您可以避免或减少当处理器试图访问非驻留内存时发生的代价高昂的页面错误。
4种关键RMM配置
现在,让我们看看如何将这些构建块组合成四种标准配置,从基本到高度优化。这些配置需要通过运行import rmm来导入RAPIDS内存管理库。
1. 标准CUDA内存
这是最基本的设置,直接使用CUDA驱动程序进行所有内存分配。这是一个很好的起点,但缺乏池化带来的性能优势。
mr = rmm.mr.CudaMemoryResource()2. 池化CUDA内存
这通常是高性能GPU计算的首选配置。它将标准CUDA资源与池分配器结合,可显著加速内存操作。
mr = rmm.mr.PoolMemoryResource(rmm.mr.CudaMemoryResource())3. 统一虚拟内存(UVM)
此配置使用托管内存,通过允许GPU和CPU共享内存来提升Polars的性能。
mr = rmm.mr.ManagedMemoryResource()4. 带预取的池化UVM
这是最先进的配置,结合了所有组件,以实现最大的性能和便利性。它为您带来了UVM的“魔力”、内存池的速度以及预取优化。
mr = rmm.mr.PrefetchResourceAdaptor(
rmm.mr.PoolMemoryResource(
rmm.mr.ManagedMemoryResource()
)
)这些内存资源可用于定义Polars GPU引擎配置,并相应地运行GPU引擎,如下所示
query.collect(engine=pl.GPUEngine(memory_resource=mr))为了在不同规模级别上比较这些配置,基准测试将在NVIDIA H200上运行——这是内存方面最大的GPU之一。我们将展示即使数据集超出GPU内存,我们也能保持性能。
| GPU | H200(带141GB VRAM) |
|---|---|
| RAM | 2TB |
| 存储 | 28TB RAID0 NVMe |
表1. 基准测试系统的硬件规格
基准测试结果
对于本次基准测试,我们使用了https://github.com/pola-rs/polars-benchmark代码库,该库本身基于TPC-H基准测试。我们对Makefile和设置进行了少量修改,以便运行批处理并收集结果。通过基准测试,我们希望弄清两件事
- 与启用UVM的配置相比,普通GPU引擎配置的性能如何?
- UVM是否允许进行大于VRAM的计算?
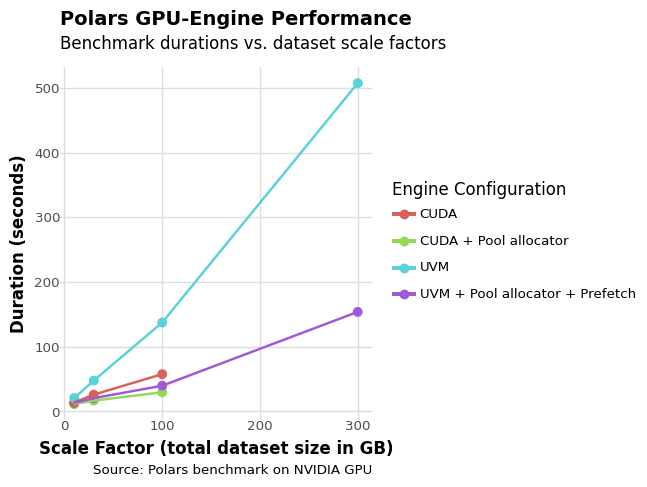 图1. 不同数据集规模下不同GPU引擎配置的基准测试结果。
图1. 不同数据集规模下不同GPU引擎配置的基准测试结果。
从该图中,我们可以观察到几个关键的性能模式,揭示了不同内存管理方法之间复杂的权衡。
- 值得注意的是,虽然UVM在300GB数据集上成功处理了所有查询而没有内存不足,但CUDA + Pool配置在处理第一个查询时失败了,尽管它在仅有141GB VRAM可用时成功处理了几乎所有其他查询。这种模式突显了查询执行的成功在很大程度上取决于特定场景的内存访问模式和要求,而不仅仅是整体内存容量。
- 池子分配器始终展现出其作为优化层面的价值,在较小数据集(规模因子10)上将基准测试运行时间减少15%,在较大数据集(规模因子300)上减少高达60%,使其成为大多数配置的简单默认选择。
- 正如预期,基础UVM配置显示出显著的性能损失,由于缺少智能页面迁移机制,其运行速度比基础CUDA配置慢1.5倍至2.4倍。在这种最坏的情况下,每次对不在VRAM中的内存访问都会触发页面错误,导致内存性能严重下降,因为项目会按需交换到VRAM中。
- 然而,当UVM结合池分配和预取时,这种性能损失显著缩小到仅比CUDA慢1.2倍至1.3倍,这证明了主动内存管理的有效性。
此外,我们可以得出结论,UVM允许执行超过没有UVM配置所能处理的内存阈值的查询。然而,这会带来轻微的性能损失。这也意味着在某些情况下,即使您的数据集太大而无法完全放入VRAM,您仍然可以在不使用UVM的情况下对其进行处理。
效果可能因情况而异
最终您应该选择哪种配置将取决于您的具体用例。主要因素包括您可用的硬件、您正在处理的数据以及您的查询形式。幸运的是,尝试这些引擎配置就像只修改.collect(...)调用一样简单。务必进行几次基准测试(使用hyperfine、py-spy或Scalene等工具),并选择最适合您的配置!