自四月宣布新的加速GPU引擎以来,NVIDIA和Polars团队一直致力于提供无缝体验,并将GPU加速引入Polars。在此测试版发布中,大多数常见操作都已覆盖,并可能从GPU加速中受益。
NVIDIA的cuDF是RAPIDS系列CUDA-X库的一部分。它是一个GPU加速的DataFrame库,利用GPU的并行处理能力显著提高处理大型数据集的性能。
通过GPU加速的Polars,用户可以期望在计算密集型查询中获得高达13倍的性能提升,相较于在CPU上运行的Polars。这使得用户能够在大数据处理工作负载增长到数亿行时,仍能保持相同的交互体验。
在这篇发布博客中,我们将解释如何开始使用、我们的设计考量以及您可以从GPU加速的Polars中期待什么。
1. Python Polars
让我们先说一个小小的遗憾。新引擎将仅在Python Polars中可用。在撰写本文时,从Rust中连接到RAPIDS并非易事,并且会付出更高的努力。只支持Python的好处是我们可以直接使用cuDF,并立即支持许多操作,同时安装过程也清晰明了。
2. 入门
如果您想立即开始,新引擎适用于符合条件的机器上的Polars 1.6.0及更高版本。通过两个简单步骤即可开始加速您的查询。
要安装GPU支持,您必须安装polars[gpu]并添加--extra-index-url
$ pip install polars[gpu] -U --extra-index-url=https://pypi.nvidia.com接下来,您可以通过将engine="gpu"传递给collect方法,在GPU上收集您的LazyFrame
query = (
transaction.group_by("cust_id").agg(
pl.sum("amount")
).sort(by="amount", descending=True)
.head()
)
# Run on the CPU
result_cpu = query.collect()
# Run on the GPU
result_gpu = query.collect(engine="gpu")
# assert both result are equal
pl.testing.assert_frame_equal(result_gpu, result_cpu)2.1 Notebooks
您可以立即在我们的交互式notebook中试用
3. 设计
3.1 目标和约束
在实现加速支持之前,我们为此项工作设定了若干高级目标:
- 我们希望保持相同的语义(显而易见);
- 我们希望利用Polars查询优化器;
- 无法在GPU上执行的查询不应失败,并应透明地回退;
- 使用GPU引擎不应要求最终用户导入不同的包;
- 我们希望支持混合GPU/CPU查询执行(尚未实现);
对我们而言,这些约束排除了“松散耦合”的方法,即GPU引擎复制Polars Python API并提供第二个实现。相反,我们实现了一种紧密耦合的方法,其中cuDF在从用户输入创建Polars IR(中间表示,下文解释)后进行钩入。这样做意味着所有语义、Python类型推断和优化都完全相同,只有执行/加速不同。
3.2 钩入
3.2.1 逻辑计划
如上所述,我们没有为Polars创建cuDF API;相反,cuDF在物理查询计划执行期间由Polars进程调用。与我们正在构建的流式引擎不同(请关注,它将非同寻常!),cuDF和Polars内存引擎在整个数据批次上工作。这有一个好处,即我们可以非常容易地将整个操作卸载到cuDF。另一个好处是优化器已将实例化提示馈送到IR中。例如,一个操作知道它应该产生多少行,因此可以真正节省大量不必要的数据实例化。
在下面的图示中,我们展示了运行Polars查询的过程以及cuDF介入的时机。让我们来详细说明一下。
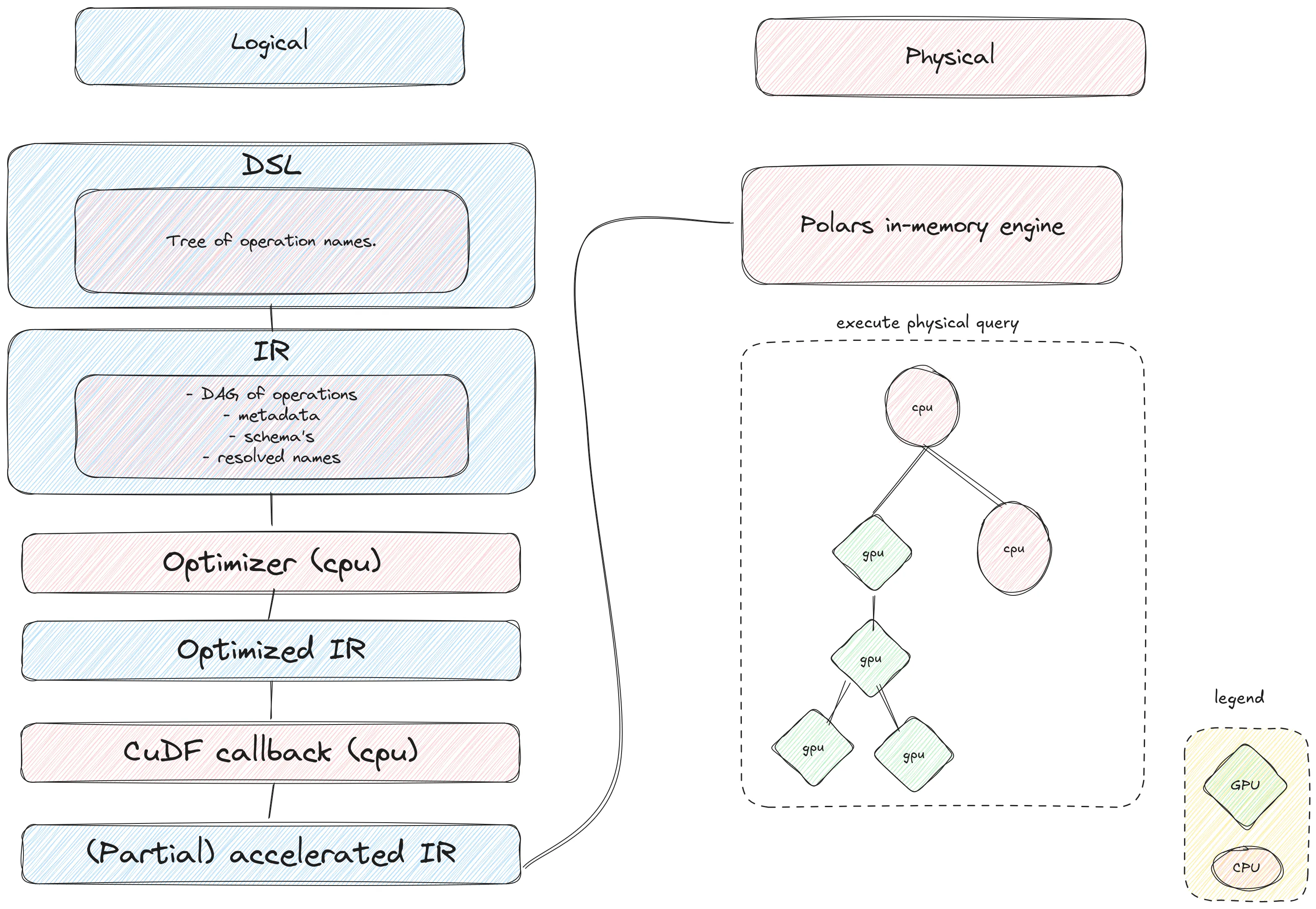
当您编写Polars查询并运行collect(engine="gpu")时,初始操作与在CPU上运行时相同。我们将构建查询的DSL(领域特定语言)。这是一个包含查询所有操作的树形结构,有点类似于编程语言的AST(抽象语法树)。
接下来,我们将DSL转换为我们的IR。在这里,我们验证查询的正确性,获取和/或估算元数据,并确定所有操作的模式。这是Polars优化器的基础输入。优化器将尝试重新排序、简化或简单地删除操作。所有这些都以缩短查询时间和降低内存使用为目标。剩下的是一个优化的IR。正是在这一点上,我们回调到cuDF。在这里,cuDF将遍历优化的IR,并尝试用一个Python回调替换DAG中的整个子图,该回调承诺返回一个具有适当模式的DataFrame。
3.2.2 CuDF回调
一旦Polars构建了优化的IR,我们就转换为GPU引擎。我们使用检查器-执行器设计。在第一阶段,我们检查Polars构建的IR,构建一个执行计划(如果可能),然后我们将该执行计划返回给Polars,并在Polars物理引擎运行时实际执行它。这使我们能够以非常低的成本提供透明的回退:我们不需要尝试在GPU上执行计划来确定它是否不受支持。
首先假设查询中的所有操作都受GPU引擎支持。在这种情况下,在遍历过程中,cuDF会构建其自己的将在GPU上执行的物理计划表示。最后,在遍历结束时,我们用一个新的(不透明函数)节点替换IR中的最顶层节点,该节点将执行GPU物理计划。然后,这个新的IR被传递回Polars内存引擎。内存引擎像往常一样执行计划,当它到达新的基于GPU的节点时,执行将转换为在GPU上运行。
那么不支持的查询呢?由于我们正在遍历的IR包含查询的完整信息(例如,所有数据类型,将要运行的操作,每个操作使用的选项),此时我们可以静态地(在执行之前)决定某个操作是否受GPU引擎支持。到cuDF的转换编码了每个操作支持的数据类型和选项集。当遇到不支持的操作时,我们停止遍历并且不替换IR中的任何节点。此时,我们最终返回一个未修改的IR给Polars内存引擎,该引擎像往常一样执行计划,就好像没有GPU参与一样。这通常会给不支持的查询增加几毫秒的开销。
尽管尚未实现,但这种方法可以扩展到GPU引擎只支持执行整个查询一部分的情况。例如,我们可能能够在GPU上运行分组聚合,但后处理步骤可能不受支持。目前,这将导致整个查询回退到CPU引擎。将来,我们将能够在GPU上执行聚合,并且只在后处理步骤时回退。
4. 基准测试
希望加速查询的用户可以从GPU硬件加速中受益。特别是计算密集型查询,例如连接、分组、字符串处理等,可以从GPU获得约10倍的速度提升。
为了验证这一点,我们在PDS-H1基准测试上运行了GPU加速的测试版。
我们将NVIDIA H100 PCIe与Intel Xeon W9-3495X(Sapphire Rapids)CPU在本地存储和80GB数据上进行了比较。结果显示,GPU加速可以将您的Polars查询速度提高高达13倍。对于CPU密集型操作,GPU加速可以带来很大的不同。基准测试表明,并非每个查询都会显著加快,但也不会降低您的性能。IO密集型查询不会从GPU加速中受益,但我们相信许多用例本质上是CPU密集型,并将从GPU加速中受益。
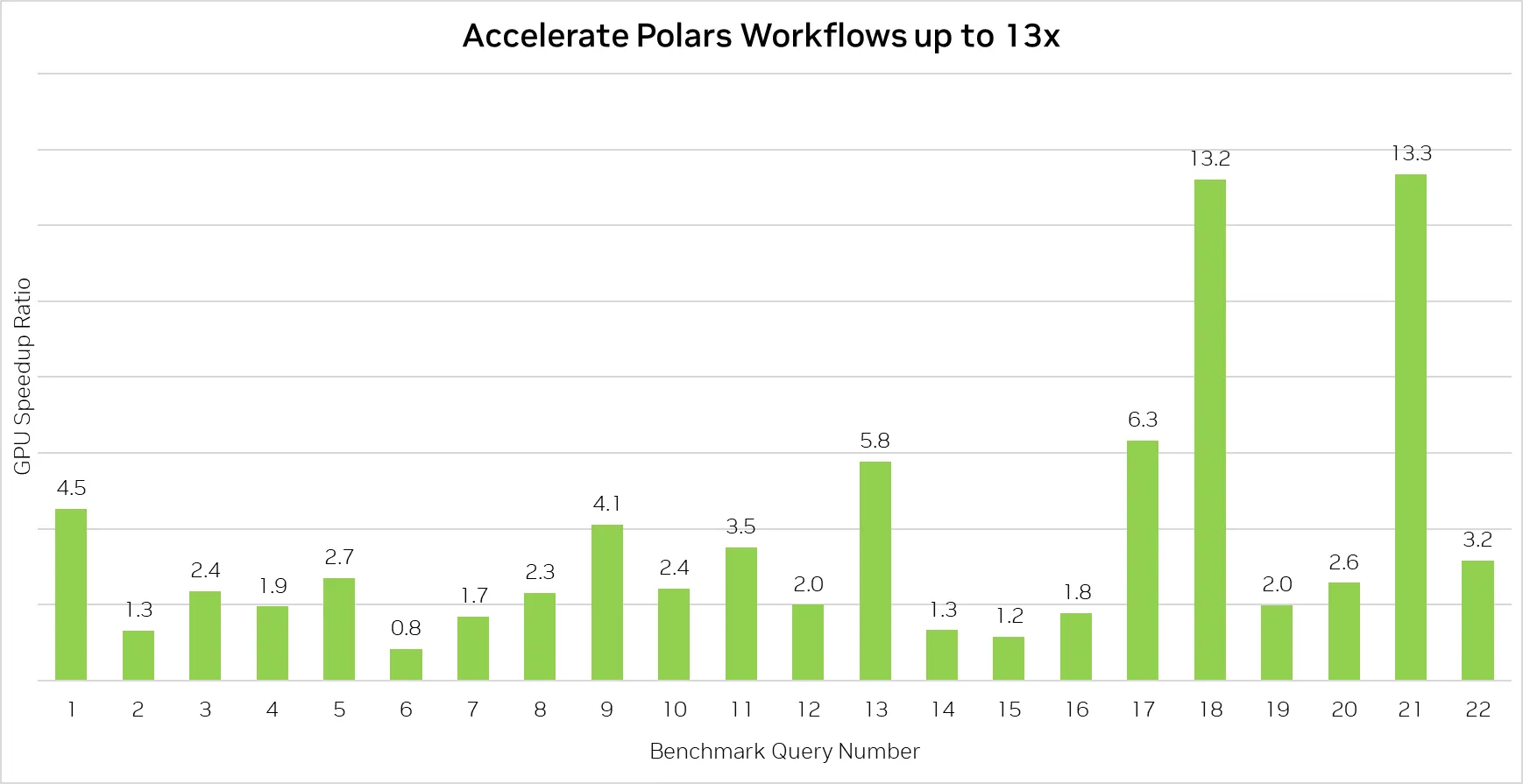 这些是Polars GPU引擎测试版与Polars默认CPU引擎在PDS-H1基准测试中,规模因子为80时,所有22个查询的加速比。
这些是Polars GPU引擎测试版与Polars默认CPU引擎在PDS-H1基准测试中,规模因子为80时,所有22个查询的加速比。
除了速度提升外,我们还注意到,随着数据集大小的增加,GPU加速的扩展性更好,这表明在更大的数据集大小上CPU瓶颈增加,而GPU的性能特性随规模增大而改善。
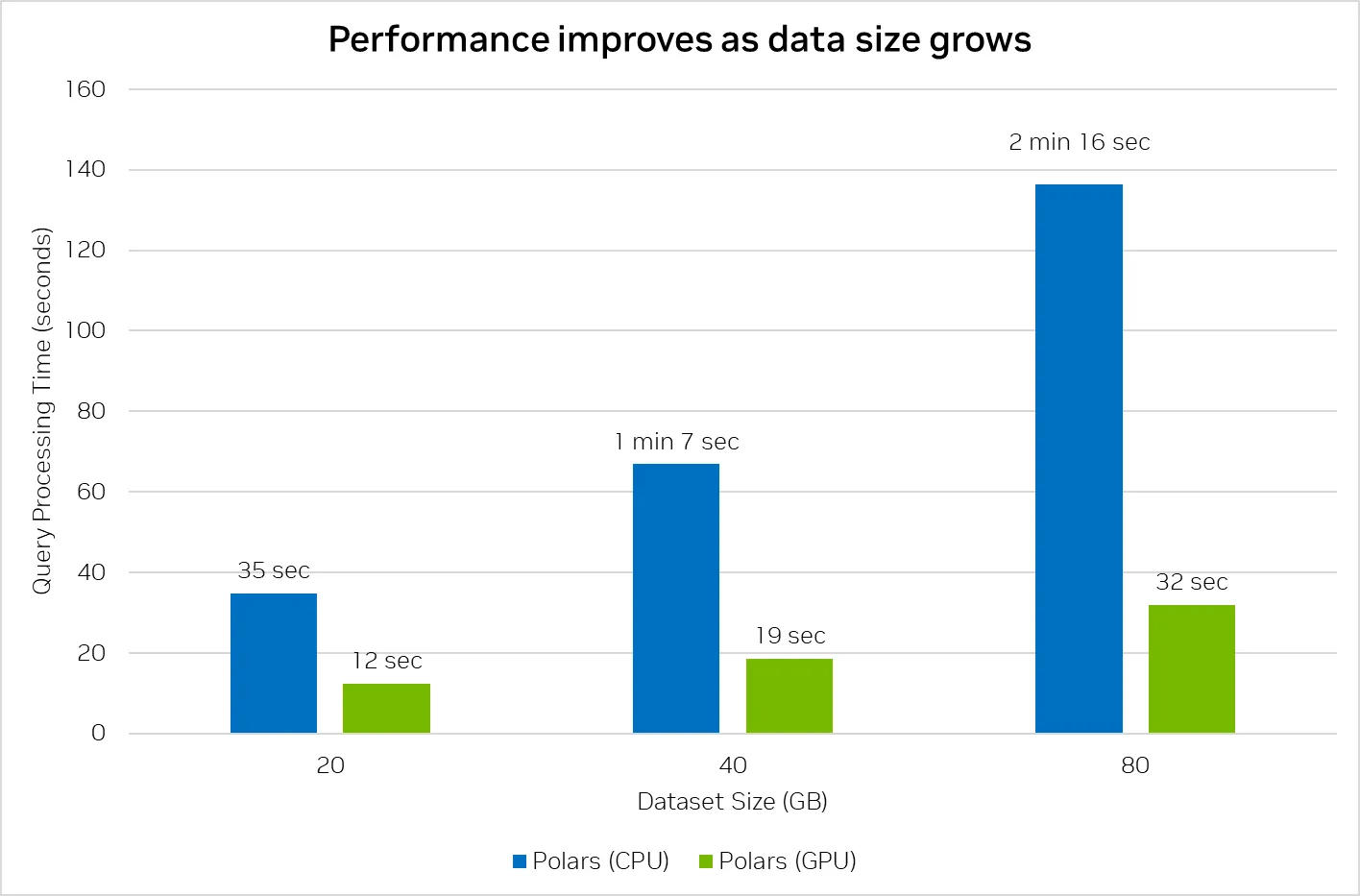 此图汇总了PDS-H1基准测试中,所有22个查询在不同规模因子下的总执行时间。
此图汇总了PDS-H1基准测试中,所有22个查询在不同规模因子下的总执行时间。
如果我们放大性能提升最大的查询,我们会发现这些查询包含大量的分组和连接操作,这使得它们成为加速的理想选择,因为它们需要大量的计算。
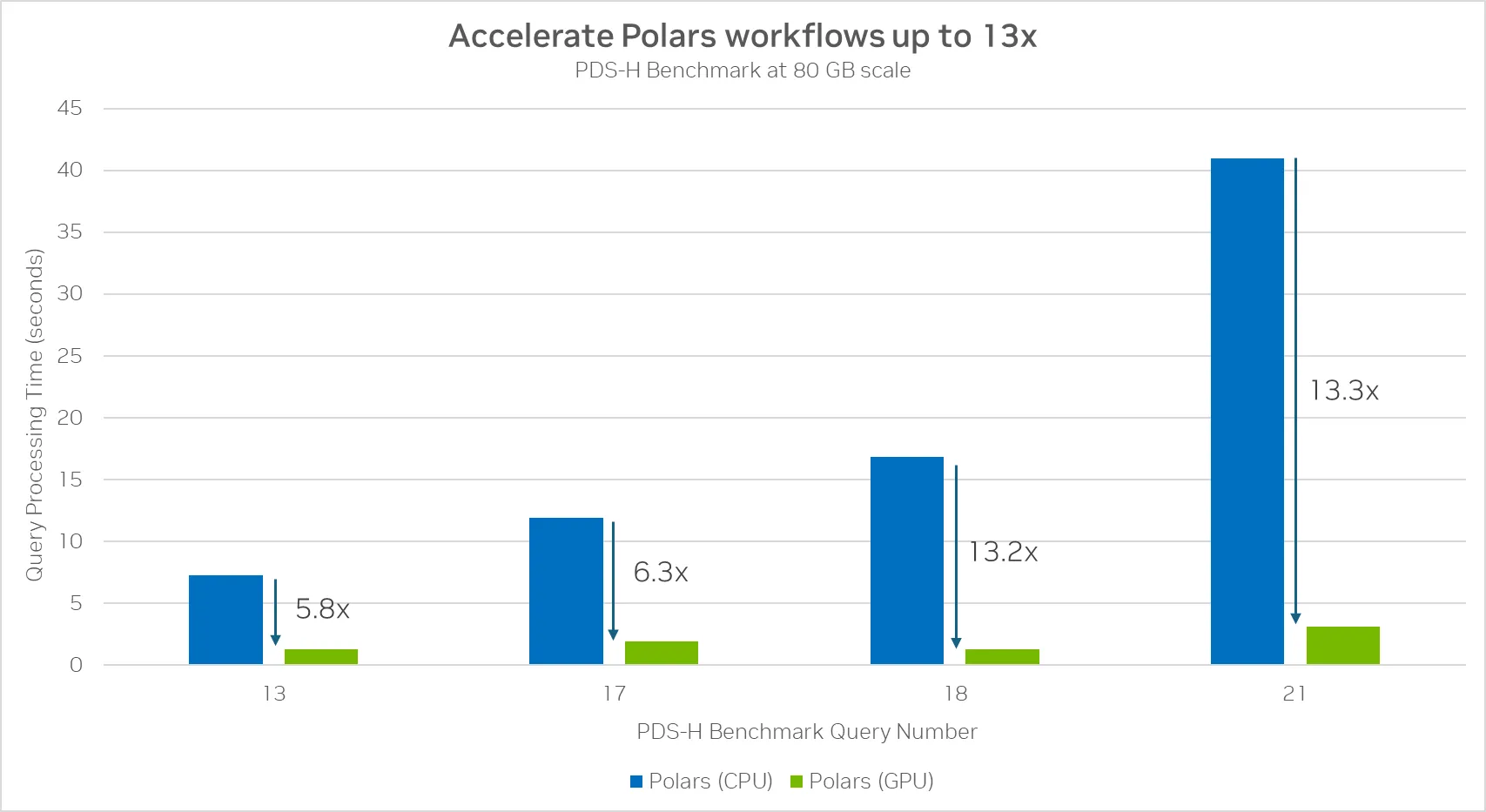 这些是在PDS-H1基准测试的22个查询中,速度提升最大的四个。由RAPIDS cuDF驱动的Polars GPU引擎在包含大量复杂分组和连接操作的查询上,相较于CPU提供了高达13倍的加速。
这些是在PDS-H1基准测试的22个查询中,速度提升最大的四个。由RAPIDS cuDF驱动的Polars GPU引擎在包含大量复杂分组和连接操作的查询上,相较于CPU提供了高达13倍的加速。
5. 附录
开放测试版注意事项
本次发布是开放测试版,这意味着您可能会遇到一些不足之处。我们建议您访问Polars用户指南,以了解此开放测试版中潜在的限制。如果您遇到任何问题或对GPU引擎有任何疑问,您可以在Polars问题跟踪器上报告,我们将与NVIDIA合作进行分类和响应。
RAPIDS
NVIDIA RAPIDS是一套CUDA-X库,供开发人员和数据科学家加速最流行的开源数据处理和机器学习解决方案。RAPIDS建立在CUDA原语之上,用于低级别计算优化,暴露了GPU并行性和高内存带宽,从而在分析和机器学习任务中实现了无与伦比的加速。
如需更多信息和咨询,您可以通过info@polars.tech直接联系我们