我们很高兴地宣布,一家围绕 Polars 打造的公司已经成立,它将实现任意规模的数据处理。
背景故事
真是一段旅程……
自 Polars 首次提交(2020年6月23日)以来,已过去三年。它最初是我的一个个人项目,目标是更多地了解查询引擎、Apache Arrow 和 Rust 编程语言。从那时起,它已经远远超出了最初的设想。
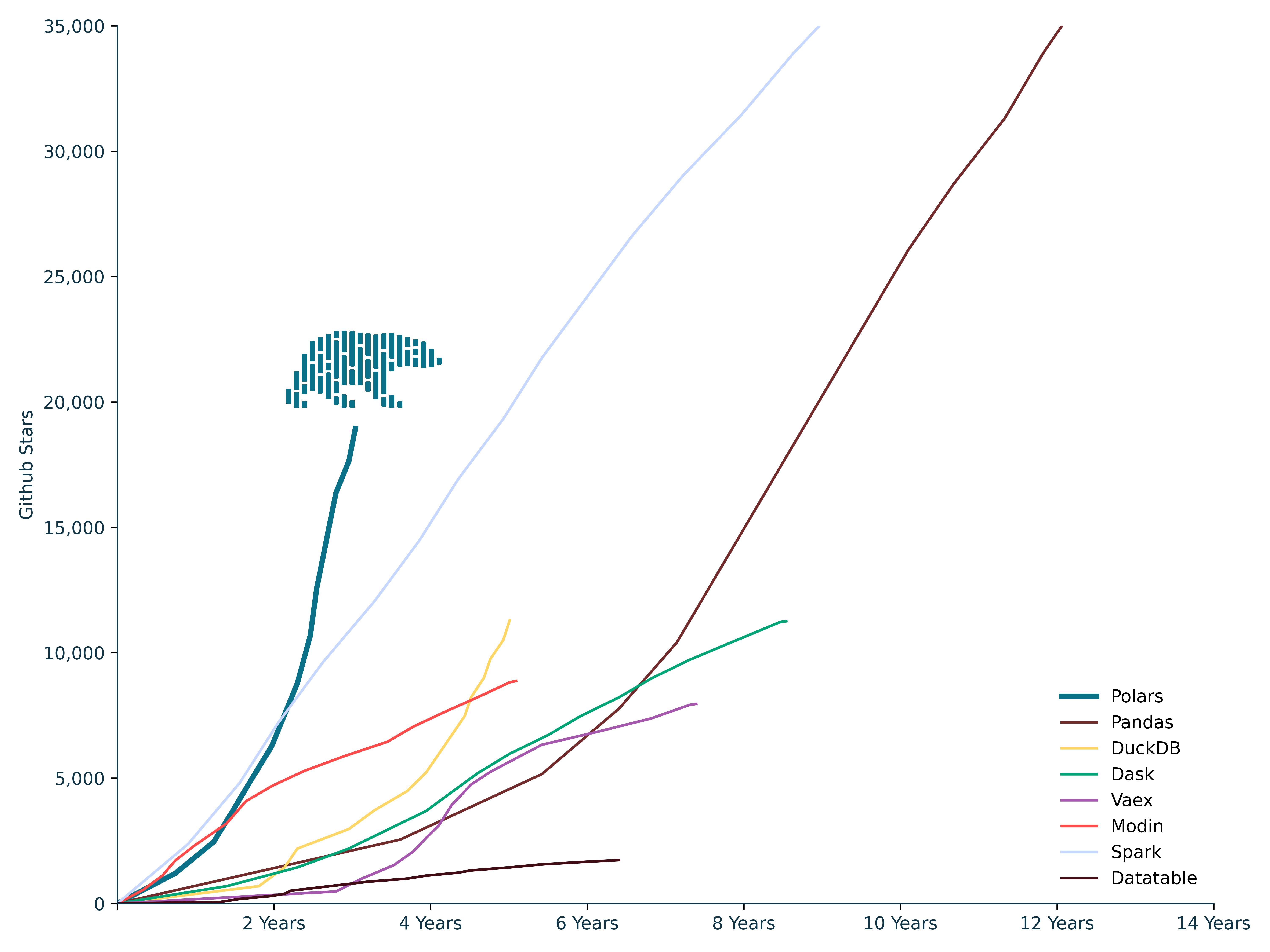
Polars 已成长为最快的开源 OLAP 查询引擎之一 [1]。其采用度也超出了我最初的预料。在 GitHub 星标方面,据我所知,该项目是增长最快的数据处理项目。截至撰写本文时,Polars 的总下载量已超过600万次,GitHub 星标数达到19,000个,正逐渐追赶上 Apache Spark 和 Pandas 这两个现有的最受欢迎的 DataFrame 实现。我非常感谢开源社区、用户以及 Xomnia 的所有帮助,没有他们,这篇博客文章就不会发布。
为什么
Polars 填补了过去十年中日益扩大的空白。开发者使用的笔记本电脑变得更强大,但也更未被充分利用。为单节点实现的 DataFrame 大多是单线程的,只利用内存,并且没有利用数据库领域中已有的传统智慧和研究成果。
Polars 是用 Rust 从头开始编写的,因此没有继承其前身们的糟糕设计选择,而是从中学习。汲取好的想法,并从错误中学习。其成功的主要驱动因素是:
- 一个严格、一致且可组合的 API。Polars 提前暴露问题并快速失败,使其非常适合编写正确的数据管道。
- OLAP 查询引擎:我将 DataFrame 视为查询引擎的前端。Polars 是一个快速向量化查询引擎,具有卓越的性能和内存使用效率。此外,Polars 还带有一个查询优化器,这意味着用户可以编写惯用代码,而优化器则专注于提高其速度。
- 我们喜欢在本地工作,并让我们的机器发挥作用。这一点最好通过引用我们某个 issue 中的一句话来解释:)
Polars 快得令人难以置信(功能也极其丰富),以至于我发现自己正在放弃 R 及其 data.table 包。确实,一个偷偷的乐趣是使用“惰性”数据框编写大量的步骤,然后在最后运行 collect() —— 然后坐下来,在 htop 中看着我的 Threadripper Pro 处理器核心开始工作。这真是啊……太棒了!
我们成立了一家公司
我们的目标是提供一个基于 Rust 的计算平台,该平台将能高效地在任意规模下运行 Polars。
我们相信 Polars API 既可用于本地环境,也可用于云/分布式环境。我们的 API 旨在在多个核心上良好运行,这种设计也使其非常适合分布式环境。我们还相信,一个基于 Rust 的列式 OLAP 引擎 (Polars) 非常适合高效的分布式计算。DataBricks 的 Photon 引擎(闭源开发)证明了这些环境不再是 I/O 密集型。他们得出结论,需要 C/C++ 级别的性能和列式内存来解除其 CPU 限制。
为了加速实现这一目标,我们成立了一家公司。我已邀请 Chiel Peters 作为联合创始人与我一起创办公司。Chiel 和我在过去五年里一直在同一家公司 (Xomnia) 工作,我非常信任他的见解和他这个人。我们成功完成了约400万美元的种子轮融资,该轮融资由贝恩资本风险投资公司领投。我们将共同推动 Polars 进入新阶段,我们非常期待开始这项工作。
Polars 开源项目
公司将围绕 Polars 开源项目构建。我们的服务将提升 Polars 在企业环境中的可扩展性和互操作性。Polars 将继续采用 MIT 许可,公司将赞助并加速 Polars 的开源开发。
短期目标
我们最初的重点将是建立托管环境、改进云连接器、缓存以及与使用 Polars 的公司建立联系。我不想在这里说得过于具体,因为那样很快就会过时。
我们需要您
我们无法独自完成这项工作,我们需要优秀的人才和优秀的公司与我们合作。
我们正在招聘
您可以成为其中的一员。如果您是一位经验丰富的 Rust 开发者,对构建数据库或编写快速软件感兴趣/有知识,请访问 https://hiring.pola.rs。我们正在招聘约4名(CET时区附近)的员工。
我们正在寻找设计合作伙伴
Polars 发展迅速。新的功能和改进每天都在增加。我们正在寻找拥有大量用例、正在使用或迁移到 Polars 的公司进行合作,以从实际用例和经验中学习。设计合作伙伴有助于识别潜在的改进领域,塑造未来计划并助推其成功。如果您有兴趣成为我们的合作伙伴,请通过 info@polars.tech 联系我们。
附录 A
DataFrame 实现的次优状态主要可归因于:
A.1 忽视数据库研究
高效数据处理是一个难题。这个问题已经被研究了很长时间,但如果你从 DataFrame 的角度来看待这个问题,你可能不会察觉到这一点。几乎所有的实现都按原样运行你的查询,并且不为用户进行任何优化。我相信 DataFrame 应该被视为一个物化视图。最重要的是其下的查询计划以及我们优化和执行该计划的方式。DataFrame 本身只是一个中间数据结构。它是一种帮助用户思考业务问题的抽象,但在我们这边,最重要的是查询引擎。
A.2 实现是用 Python 编写的。
因为 Python 是最流行的 DataFrame 实现的主语言,以及已经可用的工具。这在 pandas 中可以清楚地看到。pandas 使用 numpy,尽管它不太适合关系数据处理。numpy 非常适合数值处理,但对于任何不适合数字的其他数据类型(数组、字符串、结构体),它需要存储盒装的 Python 对象。这已经被接受了十年多。对于 Rust 程序员来说;一列会有点类似于 `Vec
任何其他利用 pandas 的工具都继承了相同的糟糕数据类型和相同的单线程执行。如果问题受 GIL 限制,我们仍然停留在单线程的 Python 世界。
A.3 闲置硬件
我的笔记本电脑有16个核心和1TB硬盘。DataFrame 实现应该充分利用这些资源并高效地运行(因此不是 Python 多进程)。