前言
近日,METRO.digital 启动了一个项目,旨在加强 METRO 在 19 个国家的关键绩效指标(KPI)创建。通过从 SQL 迁移到 Python 并利用 Polars,他们在效率、可读性和可维护性方面取得了显著提升。
在本案例研究中,Patrick Bormann 博士(技术主管数据科学家)分享了他团队的经验。
关于 METRO.Digital
METRO.digital 是麦德龙(METRO)旗下的技术产品主导型公司,麦德龙是全球领先的批发和食品贸易专家。麦德龙在全球 30 多个国家运营,在超过 623 家批发商店和 94 个配送中心销售产品,并拥有在线市场 METRO MARKETS。
凭借在全球批发领域多年的经验,METRO.digital 为所有麦德龙国家开发定制的全球 IT 服务和产品。METRO.digital 的员工分布在德国、罗马尼亚和越南,他们持续致力于一个目标:批发行业的数字化。
关于项目
我们的团队专注于数据科学,特别是机器学习中的因果推理,侧重于假设情景,并利用业务和产品 KPI 来增强我们的因果推荐系统。我们旨在通过加速决策制定和在战略性商品组合缩减方面提供更好的洞察力来支持批发业务中的品类经理做出决策,因为人类可能无法注意到复杂决策系统中的所有细节。我们最近的项目涉及将基于 SQL 的 KPI 创建转换为使用 Polars 的基于 Python 的流程。
主要目标:提高可维护性、可读性,并为未来的 KPI 增强做好准备
我们的任务是将每个 KPI 的 50 个 SQL 文件转换为 Python 代码,同时保留全球 19 个国家(其中大部分在欧洲)的原始 KPI 逻辑。
我们的主要验收标准之一是,发票数据加载到内存必须快速,预处理速度甚至更快,以便在笔记本环境中工作时,开发过程中对 KPI 进行未来增强的更改能够立即显现。
我们需要这种即时反馈,因为我们不确定代码的哪些部分可以保留,哪些部分需要增强,以及哪些部分可能甚至存在错误,因为这些代码不是我们自己的,而是继承来的。然而,速度并不是这里的唯一关键因素,因为对于单个 KPI 如此多的文件,你无法很好地掌握代码的运行情况。尽管我们知道文件的数量和命名遵循特定的数据仓库结构,但在这种情况下,更高的可读性和更简单的维护性却缺失了。然而,对我们来说,这些方面与数据加载和预处理的速度一样重要。
为了了解我们处理的数据量:我们最大的国家之一拥有超过 9.3 亿行和多列数据,涵盖两年。加载带有模式覆盖的数据仅需 8 分钟,数据预处理则在几秒内完成。
拥有良好的先验经验
尽管我们已经决定将每个 KPI 的 50 个 SQL 文件迁移到 Python,以使 KPI 创建更具可读性和可维护性,但问题当然是使用哪种工具。确实可能存在其他替代方案,例如 PySpark。然而,我们在因果推荐项目中使用 Polars 方面拥有先前的经验,可以说是一个良好的先验。然而,这种经验仅限于标准的 Polars 库。在此之前,我们只处理过数百万行数据,而不是包含 1.8 亿、4.6 亿甚至高达 9.3 亿行发票数据的数据帧(正如您稍后将看到的)。我们非常确定在这种规模下进行连接操作可能相当具有挑战性。最终,我们决定尝试一下,并选择了 polars-u64-idx 库 1,并进行了实验。
自上而下的可读性
通过迁移到 Polars,我们希望获得一种清晰且结构化的数据创建方式。事实上,自上而下地阅读 Polars 代码比在一个 SQL 文件中跳转更容易。为了了解典型查询的样子,请参阅下面的两个代码片段。
CREATE OR REPLACE TABLE `${p_number}.${dt_ident}.product_dimensions`
AS
SELECT
v.article_number,
v.variant_number,
v.article_brand_name,
v.date_of_deletion,
ph.stratified_id,
(v.customer_number * 1000000000) + (v.article_number * 1000) + v.variant_number AS p_ATT_key,
1 AS adjacent_sales,
CASE
WHEN a.own_article > 0 THEN 1 ELSE 0
END AS is_own_article,
(a.cat_level_one * 100) + a.cat_level_two AS grp_number
FROM `our-company-${country}-production_level.datawarehouse.variation` AS v
INNER JOIN `our-company-${country}-production_level.datawarehouse.articles` AS a
USING (customer_number, article_number)
LEFT JOIN `${p_number}.${dt_ident}.blocking_codes` AS pabcd
USING (article_number, variant_number)
LEFT JOIN `${p_number}.${dt_ident}.product_levels` AS pl
USING (article_number)
WHERE v.article_number > 0
AND COALESCE(pabcd.block_code, 0) < 5
AND pl.stratified_id NOT IN (60, 61)以及使用 Polars 时
product_dimensions = (
variation
.join(articles, on=["customer_number", "article_number"], how="inner", suffix="_a")
.join(blocking_codes, on=["article_number", "variant_number"], how="left", suffix="_pabcd")
.join(product_levels, on="article_number", how="left", suffix="_pl")
.filter((pl.coalesce(['block_code', 0]) < 5) & (~pl.col('stratified_id').is_in([60, 61])))
.with_columns(
((pl.col("customer_number")) + (pl.col('article_number') * 1000) + (pl.col('variant_number'))).alias("p_ATT_key"),
)
.select(
'article_number',
'variant_number',
'article_brand_name',
'stratified_id',
'p_ATT_key',
'grp_number'
)
)尽管有些人可能认为 SQL 看起来更具结构性或更容易阅读,但您可以看到,这次迁移揭示了不必要的过滤器、变量和臃肿的客户范围数字,这些都再次增加了 KPI 创建过程的负担。
尽管成本削减并非我们的主要目标,但我们对通过移除这些不必要的计算所获得的效率提升表示赞赏。
测试惰性计划的管道操作
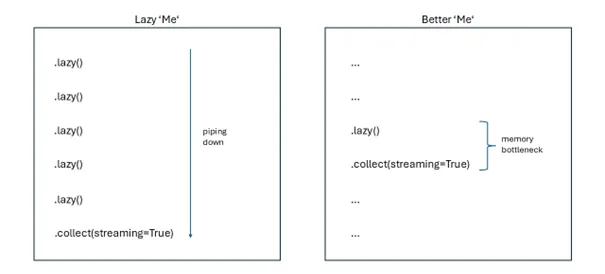
在迁移到 Polars 的过程中,我们测试了使用流式引擎对多个惰性帧进行管道操作,希望优化后的计划能够减少计算资源,尽管这可能会延长 KPI 的计算时间。
盲目使用这种方法导致了崩溃,甚至增加了计算资源的使用。此外,将多个计划进行管道操作也造成了混乱,因为许多未命名的子计划被挤压成一个最终的大计划。但这是否是开发人员的本意,即它可以用于此目的?也许我们在这里做错了什么。也许我们应该使用图形来更好地解释所有管道化的计划。我们记得在预检中,我们已经限制了 KPI 创建过程中所需的列,这是否在一开始就限制了优化?最终,选择性使用效率更高,正如下一段所示。
使用 LazyFrames 优化连接操作
我们没有将计划强行塞入管道,而是识别出代码中的特定瓶颈,即数十亿行数据帧的连接操作可以受益于惰性帧和流式引擎。这项优化将计算资源需求减少了 128GB 内存和 16 个 vCPU,从而允许使用更小的机器类型。
下图显示了其他几个国家的总内存减少量。尽管该表并未完全说明所有情况,因为计算中缺少一些国家,但我们假设在惰性计划中处理的发票数据越大,您在计算资源方面节省的就越多2。
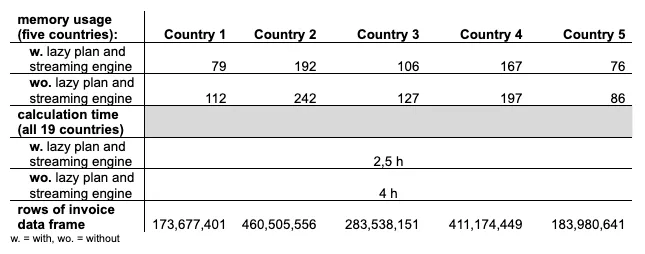
因此,我们没有自己偷懒,而是决定投入时间来思考流式引擎在何处才有意义。
Dtypes 的自动收缩
我们还尝试了使用 Polars 内部的 shrink_dtype 方法进行 dtypes 的自动收缩。尽管收缩可能会很混乱,特别是对于要连接的键,但为跨多个数据帧的键选择更大的联合 dtype 使其生效。然而,收缩在 Polars 1.5.0 中导致了错误的聚合,因此我们决定跳过计算中所需列的收缩。但事实证明,它对于计算中的辅助列而非主要组件很有用。然而,在 1.26.0 版本(撰写本文时的最新版本)中,我们完全没有遇到任何问题。
assortment_levels = (
df_info_numbers
.with_columns(pl.col("company_id").cast(parent["parent_id"].dtype))
.join(parent, left_on="company_id", right_on="parent_id", how="inner")
.filter(
(pl.col('date_from') <= date.today()) & (pl.col('date_to') >= date.today())
)
.pipe(shrink_dtypes)
.with_columns(
pl.col("article_number", "grp_number").cast(invoice["article_number"].dtype),
)
)总而言之,收缩帮助我们在 KPI 预处理过程中进一步减少了 RAM 资源。我们发现占用的内存大小减少了 50%,这可能非常可观,特别是对于大型数据帧。总体而言,惰性操作和收缩是减少所需资源的主要贡献者。
结论
使用 Polars 从 SQL 迁移到 Python 在可读性、可维护性和成本削减方面带来了显著好处,为我们未来增强 KPI 铺平了道路。我们的项目展示了使用 Polars 创建 KPI 的明显优势,我们很高兴能在未来的项目中继续利用这一先进框架。